Python地址轉換地圖經緯度
前言
在實作地圖的時候多少會遇到資料只有地址的情況
以最常見的Google map來說,要標記一個地點就需要經緯度
當然Google本身也有提出對應的API → Geocoding(地理編碼)服務
簡單來說能直接把地址經查詢後轉經緯度回傳,當回傳次數一多就會有收費的問題了…
那這時候需要處理大量資料的工程師怎麼辦呢?
- 台灣內政部有提供一個全國門牌地址地位服務
(門牌地址地位服務)
該服務要申請會員,每日上限10000筆
只要選擇篩選的情況(接受模糊地段等),將資料整理成規定格式上傳後,處理完後會寄到信箱(約一小時左右)
就我嘗試過的情況來說,太嚴格幾乎是抓不到東西,沒怎麼設定可能地址對照出來是別的街道…
Python 網頁爬蟲,透過電腦控制網頁開啟執行重複的動作取得經緯度,也是本文要說的重點
在資訊如此發達的現代,網路上爬蟲教學文多到不行,我也試著留下作法讓後人可以少走冤枉路
執行環境
以下程式碼在 Python3.6.8 可以使用,3.4以上的應該都適用
若電腦沒裝python,請去python官網
- Downloads
- All releases
- 選擇適合版本
- 直接安裝到底
終端機(cmd)執行以下指令可以看python版本
python -V
安裝Python自動化模組(官方文件)
1 | pip install selenium |
當然要開什麼瀏覽器需要去抓那瀏覽器對應的驅動程式(**Driver.exe)
以Google瀏覽器為例(驅動程式下載),選擇自己Chrome的版本下載
怎麼看自己的Chrome版本
- 點選網頁右上角頭像旁邊三個點
- 選擇設定
- 關於Google
下載完記得跟Python程式放在同一資料夾
安裝偽裝用戶代理模組
1 | pip install fake_useragent |
爬蟲若是爬得過於頻繁就會被網頁偵測到,這時候只能在開啟的網頁下點功夫,舉例來說,正常開啟網頁做操作會有個請求的表頭,下面這段就是正常打開做請求的時候會送出的Useragent(用戶代理)
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36
會顯示用戶作業系統、瀏覽器版本等等的資訊,有些網頁擋爬蟲是看這個(部分是看IP請求次數)
若重複的代理一直送請求容易很快就被擋,這地方做點偽裝延後被擋的時間
Python程式
接著就是選定要爬蟲的網頁,以台灣電子地圖服務網為例子
以下程式碼會依 功能 分部分做解說
網頁自動化
1 | from selenium import webdriver |
上面程式碼執行後會開啟目標網頁,不做任何動作
瀏覽器此時會有一則提示寫著:目前被自動化程式控制
另外開啟的瀏覽器也有設定可以調整,以下提供幾個參考
1 | from fake_useragent import UserAgent |
接著說明模組基本操作的方式,由於該模組是模擬人在網頁上的操作,只要網頁上有的東西都能抓
提供以下方式抓取網頁元素
find_element_by_id
find_element_by_name
find_element_by_xpath
find_element_by_link_text
find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector
有網頁開發基礎的應該不陌生,網頁元素都會有一些屬性存在
例如我要在台灣電子地圖上找到搜尋框,那我程式碼基於上面基礎可以再加上
1 | addr = '臺北市中正區延平南路96號' |
這程式會使網頁自動輸入地址並送出
不知道怎麼看網頁名稱的可以按下F12,選擇想看元素的位置就會右邊原始碼部分就會亮起
如果要用xpath定位參考下圖所示,複製到的就是網頁元素的XPATH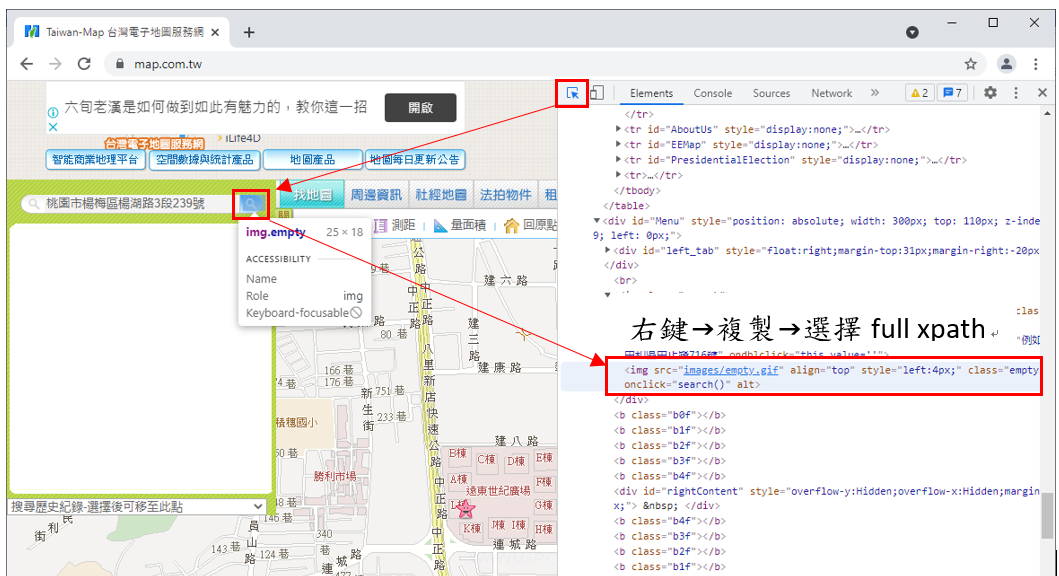
其他抓取元素的資訊一樣透過這方法來看,會了這個之後基本上就是熟悉語法的問題了
熟悉操作流程後來整理一下網頁的動作需求
- Python開啟網頁
- 在地圖搜尋框輸入特定地址後送出
- 找到位置後會出現該地址的資訊
- 點選座標的按鈕後網頁會顯示該地點經緯度
- 取得網頁顯示的經緯度後回傳
- Python關閉網頁
整理好需求後程式會長這樣,把流程寫成一個Python函式,地址在呼叫的時候給
1 | def get_coordinate(addr): |
到這邊地址轉經緯度功能差不多做完了,剩下就是一些程式上的優化
當然如果是少量資料這樣跑肯定是沒什麼問題,大量跑起來就會有一些問題出現了
網頁爬蟲多次後讀取超時
連續開啟網頁多次後,網頁元素還沒有載入完成程式就要存取就會出錯
因為抓不到元素又沒寫例外處理,程式就會直接中斷執行,此時可以加上
1 | from selenium.webdriver.support.ui import WebDriverWait |
這段程式碼意思是在存取時等待一段時間存取,存取到才會給網頁元素,沒有就會進入TimeoutException
我的情況是在抓顯示目標地址iframe時候會出現,所以我選擇延後抓取時間,若60秒沒抓到就進例外處理
Python例外若沒進行處理會強制中止程式執行,處理例外可以這樣寫
1 | from selenium.common.exceptions import TimeoutException |
讓函式回傳(1,1)表示出現例外情況,讓程式可以自己判斷接下來的操作而不是被強制中止
網頁爬蟲多次後被偵測成機器人
連續開啟網頁多次後,目標網頁暫時封鎖你的存取使程式無法取得資料
一般來說網頁都會做反爬蟲的機制,因為大量的爬蟲會消耗伺服器的資源,會導致一般用戶的體驗受影響,爬蟲還是要適可而止啊…
一旦被判定成機器人,就直接鎖存取的IP了,此時要再度存取只能換IP來規避封鎖
當然這部分也需要例外處理不然程式照樣中止給你看,寫法可參考
1 | from selenium.common.exceptions import UnexpectedAlertPresentException |
降低被偵測成機器人的機率
前面也有提到更換請求的用戶代理讓網頁伺服器誤判請求來源,有些情況反而會使原本能抓到的元素抓不到要注意(瀏覽器版本過於老舊某些元件可能不支援或不存在等)
再來就是在完成每次請求資料的時間點讓程式休息一下,python內建語法可使用(單位:秒)
1 | import time |
最好加上隨機變化的休息時間來降低被偵測的機率
1 | import time |
讀取CSV檔案
這邊提一下我在做這功能時用到的模組,以常見的CSV檔案為例
假設我今天要處理的CSV檔案內容是
楊文昌診所,高雄市林園區東林西路281號
澄品牙醫診所,高雄市林園區林園北路384號
大統內兒科診所,高雄市大寮區鳳林四路五十六號
以上資料是我從政府開放性平台取得,原生檔案並沒有經緯度存在
那我就能讀取檔案後將內容存在變數 datas 中
1 | import csv |
輸出CSV檔案
將上面取得的經緯度依需求整理成特定格式CSV檔案並儲存輸出到電腦上
1 | import csv |
這邊注意with open的第二個參數
- ‘w’:是每次寫入都重頭開始,若沒找不到檔案會自己產生一個
- ‘a’:寫入是從檔案的最後一行開始,不會自己產生檔案
以上便是我透過網頁爬蟲去將地址轉成經緯度的python程式碼
當然這方法懂之後所有網頁都能適用,網頁反爬蟲的機制也不只被ip封鎖那麼簡單了
像是輸入驗證碼或是圖像驗證之類的在現代網頁反爬蟲也不少見就是,當然也有破解法又是別的故事了…
要成為一名精通網頁爬蟲的工程師之路是很廣闊的啊 ~